本文分析一起线上Redis扩容引起的业务故障的排查过程。
问题描述
近日,我们在执行线上Redis集群扩容任务时发生了业务报错. 我们首先按照如下步骤迁移:
- 启动Redis实例
- 新实例加入集群, 划分主从
- 迁移slot数据
然而,在关键的第三步——数据迁移环节,意外来了,业务应用遭遇了缓存访问异常,具体表现为以下错误提示(注:此处省略了具体的报错堆栈,以保持文章简洁性):
MOVED 10909 10.100.8.109报错来源是从我们使用的Lettuce客户端抛出的(Lettuce是一个Java Redis客户端库). 而且还发现一个特点: 并不是所有请求都报错, 报错的是那些请求量较大的应用, 且当时slot正在迁移的key.
遇到这个问题你能猜到是什么原因呢? 接下来跟着我一起分析.
问题排查
显然,错误信息与Redis的MOVED响应紧密相关。为了准确解决此问题,我们首要任务是深入理解MOVED响应的本质。
什么是MOVED响应
MOVED响应出现在如下情况:
假设我有两个节点A和B, A拥有0~10这些slot, B有11~20这些slot, 假设一个key=a, 它正好落在节点A应用的slot中, 如果我们向节点B发送get a命令, 那么B会返回MOVED异常, 同时返回给我们A的地址, 意思是a在A上, 应该向A发送get命令.
前面我们讲到第三步迁移slot数据, 这一步的具体操作流程是什么呢? 看下面的例子:
假设我们有如下包含三个master的集群, 通过cluster nodes命令可以看到三个master节点拥有的slot:
127.0.0.1:6435> cluster nodes
9a1be71bd5699ecb62b4308212ba1363ea72020f 10.100.140.233:6435@16435 myself,master - 0 1716880300000 79 connected 10920-16383
86107b968a281aedbcddd9267b53dfb4bcaadee4 10.100.140.230:6437@16437 master - 0 1716880302000 80 connected 0-5454
ba7481602474ce44fa964af043c9417670246002 10.100.140.232:6437@16437 master - 0 1716880302186 74 connected 5455-10919可以看到15495这个slot在10.100.140.233上,现在我们移动这个slot到10.100.140.230上。
| nodeId | ip | |
|---|---|---|
| 源节点 | 9a1be71bd5699ecb62b4308212ba1363ea72020f | 10.100.140.233 |
| 目标节点 | 86107b968a281aedbcddd9267b53dfb4bcaadee4 | 10.100.140.230 |
首先在10.100.140.230上执行:
127.0.0.1:6437> cluster setslot 15495 importing 9a1be71bd5699ecb62b4308212ba1363ea72020f
OK这个命令在目标节点上执行, 设置15495这个slot的状态为importing, 来源是10.100.140.233(它的nodeId就是9a1be71bd5699ecb62b4308212ba1363ea72020f)
再执行cluster slots可以看到10.100.140.230这个节点上15495这个slot的状态:[15495-<-9a1be71bd5699ecb62b4308212ba1363ea72020f], 说明正在从9a1be71bd5699ecb62b4308212ba1363ea72020f这个节点上迁移.
127.0.0.1:6437> cluster nodes
9a1be71bd5699ecb62b4308212ba1363ea72020f 10.100.140.233:6435@16435 master - 0 1716880617000 79 connected 10920-16383
86107b968a281aedbcddd9267b53dfb4bcaadee4 10.100.140.230:6437@16437 myself,master - 0 1716880618000 80 connected 0-5454 [15495-<-9a1be71bd5699ecb62b4308212ba1363ea72020f]
ba7481602474ce44fa964af043c9417670246002 10.100.140.232:6437@16437 master - 0 1716880619167 74 connected 5455-10919然后在源节点上执行:
127.0.0.1:6435> cluster setslot 15495 migrating 86107b968a281aedbcddd9267b53dfb4bcaadee4
OK这个命令在源节点上执行, 设置15495这个slot的状态为migrating, 然后执行cluster nodes命令查看当前slot分布:
127.0.0.1:6435> cluster nodes
9a1be71bd5699ecb62b4308212ba1363ea72020f 10.100.140.233:6435@16435 myself,master - 0 1716880693000 79 connected 10920-16383 [15495->-86107b968a281aedbcddd9267b53dfb4bcaadee4]
86107b968a281aedbcddd9267b53dfb4bcaadee4 10.100.140.230:6437@16437 master - 0 1716880694125 80 connected 0-5454
ba7481602474ce44fa964af043c9417670246002 10.100.140.232:6437@16437 master - 0 1716880692116 74 connected 5455-10919可以看到10.100.140.233上显示15495这个slot正在迁移给86107b968a281aedbcddd9267b53dfb4bcaadee4(10.100.140.230)这个节点.
现在我们只是分别在源节点和目标节点上设置了slot的状态, 还没有迁移, 现在我们开始迁移一个key:
migrate 10.100.140.230 6437 a 0 5000 replace这里我们在10.100.140.233上执行, a就是我们要迁移的key.执行之后, key在源节点上被删除并且写入到目标节点上.
这时候在源节点上执行get a会发生什么呢?
127.0.0.1:6435> get a
(error) ASK 15495 10.100.140.230:6437可以看到, a由于已经被迁移, 所以这里Redis Server会返回ASK {slot} {target_ip}, 告诉我们要在10.100.140.230这个节点上获取.
ASK和MOVED响应的区别是什么?
ASK响应只会出现在slot迁移的过程中, 发送命令到源节点上, 而源节点上此时没有这个key, 这时候可能出现两种情况:
1.这个key本身不存在
2.这个key已经迁移到目标节点了
而Redis不能分辨是哪一种, 因此让客户端去ASK一下目标节点, 如果目标节点有那就是第二种情况, 如果没有, 说明是第一种情况
但直接在10.100.140.230上执行get a可以吗? 不可以! Redis会返回MOVED异常, 指向源节点10.100.140.233:
127.0.0.1:6437> get a
(error) MOVED 15495 10.100.140.233:6435正确方式需要这么获取:
127.0.0.1:6437> asking
OK
127.0.0.1:6437> get a
"value"先发送asking命令再执行get a, 就可以获取到正确的响应.
总结
这一节中我们说明了迁移过程中为什么MOVED响应会出现,以及客户端该如何处理MOVED和ASK响应, 但仍然没办法解释为什么客户端会出现异常? 这就需要接下来分析Lettuce客户端的实现了.
Lettuce的实现
我们首先看当Lettuce收到了MOVED响应和ASK响应会做什么(我们使用的是Lettuce 5.0.7版本)
public void complete() {
// 当收到MOVED响应或者ASK响应
if (isMoved() || isAsk()) {
// 计算重试次数, 如果超过最大值maxRedirections就不再重试
boolean retryCommand = maxRedirections > redirections;
redirections++;
if (retryCommand) {
try {
// 重试
retry.write(this);
} catch (Exception e) {
completeExceptionally(e);
}
return;
}
}
super.complete();
completed = true;
}
public boolean isMoved() {
if (getError() != null && getError().startsWith(CommandKeyword.MOVED.name())) {
return true;
}
return false;
}
public boolean isAsk() {
if (getError() != null && getError().startsWith(CommandKeyword.ASK.name())) {
return true;
}
return false;
}逻辑非常简单, 如果当前重试次数超过最大值maxRedirections就不再重试直接退出, 否则通过调用retry.write(this)再次重试, 让我们看retry.write(this)做了什么, 它主要的逻辑:
- 如果当前的命令响应是MOVED或者ASK, 则根据命令参数中的第一个key计算slot
- 获取MOVED和ASK响应中的目标ip地址
- 然后调用
asyncClusterConnectionProvider.getConnectionAsync获取连接 - 在这个连接上写入命令, 注意这里传入了asking参数, 代表是否是ASK响应需要ASKING命令
private <K, V, T> RedisCommand<K, V, T> doWrite(RedisCommand<K, V, T> command) {
if (command instanceof ClusterCommand && !command.isDone()) {
ClusterCommand<K, V, T> clusterCommand = (ClusterCommand<K, V, T>) command;
if (clusterCommand.isMoved() || clusterCommand.isAsk()) {
HostAndPort target;
boolean asking;
if (clusterCommand.isMoved()) {
target = getMoveTarget(clusterCommand.getError());
asking = false;
} else {
target = getAskTarget(clusterCommand.getError());
asking = true;
}
CompletableFuture<StatefulRedisConnection<K, V>> connectFuture = asyncClusterConnectionProvider
.getConnectionAsync(Intent.WRITE, target.getHostText(), target.getPort());
if (isSuccessfullyCompleted(connectFuture)) {
writeCommand(command, asking, connectFuture.join(), null);
} else {
connectFuture.whenComplete((connection, throwable) -> writeCommand(command, asking, connection, throwable));
}
return command;
}
}
// .. 省略
}接下来继续分析writeCommand方法的实现, 这个方法就非常简单了.
private static <K, V> void writeCommand(RedisCommand<K, V, ?> command, boolean asking,
StatefulRedisConnection<K, V> connection, Throwable throwable) {
try {
if (asking) { // set asking bit
connection.async().asking();
}
writeCommand(command, ((RedisChannelHandler<K, V>) connection).getChannelWriter());
} catch (Exception e) {
command.completeExceptionally(e);
}
}可以看到, 如果asking为true, 说明要先发送一个asking命令, 然后再发送实际的命令.
所以看上去整个逻辑是符合预期的, 即使Slot正在迁移也能找到正确的目标Redis节点发送命令, 为什么还会报MOVED异常呢?
原因定位
我们要保证的是asking命令和下面真正要发送的命令应该要紧接着发送, 假设其中插入了一个无关的命令, 就会导致我们真正想要发送的命令得到MOVED异常!
我们观察上面的代码:
private static <K, V> void writeCommand(RedisCommand<K, V, ?> command, boolean asking,
StatefulRedisConnection<K, V> connection, Throwable throwable) {
try {
if (asking) { // set asking bit
connection.async().asking();
}
writeCommand(command, ((RedisChannelHandler<K, V>) connection).getChannelWriter());
} catch (Exception e) {
command.completeExceptionally(e);
}
}按理说asking和真正命令之间是没有其他命令插入的, 但如果lettuce的连接是多线程共享的呢?
通过查阅Lettuce官方文档:Pipelining and command flushing · redis/lettuce Wiki · GitHub (github.com)和debug源码我们确定了Lettuce确实会在多线程之间共享连接!

共享连接会出什么问题呢? 我们来推演一下:
假设此时我们有一个节点正在做slot迁移, 从n1 正在移动给 n2, slot中一个key=a已经从n1迁移到了n2.
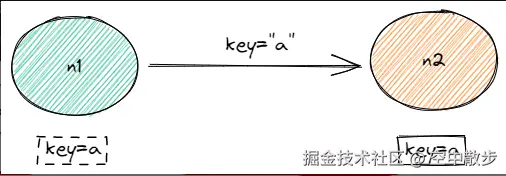
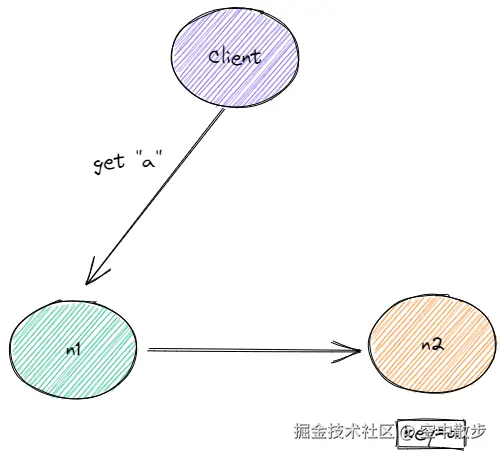
客户端此时只知道slot仍然属于n1, 因此如果客户端访问key=a, 使用命令get a, 这时仍然会发送命令到n1.
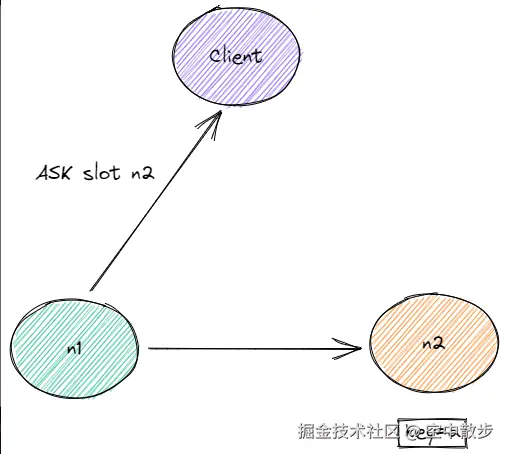
n1返回ask slot n2: 因为这时n1上已经没有a这个key了, 所以它返回ask slot n2.
客户端发送asking命令: 客户端收到ASK响应知道了这个slot正在迁移, 因此它重新发送命令到n2, 但由于是ASK响应, 所以在真正发送命令之前需要先发送asking命令.
紧接着客户端发送一个无关的命令到n2: 由于客户端到n2的连接是多线程共享的, 所以客户端可能在发送真正命令之前发送了一个无关的命令到n2
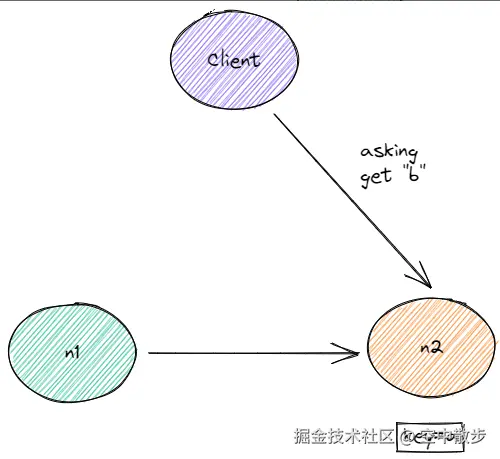
客户端发送get a到n2
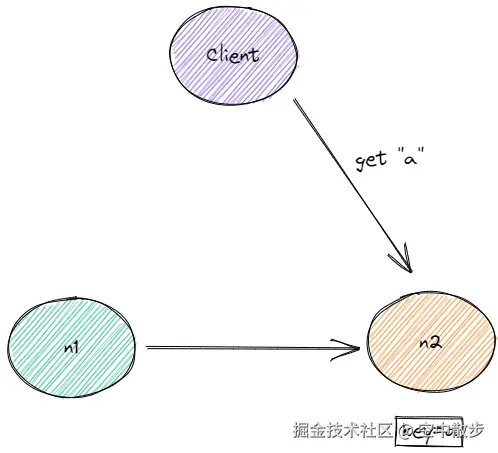
服务端返回MOVED slot n1: 由于slot正在迁移中, 而且客户端发送的get a之前没有asking, 导致n2返回MOVED响应:
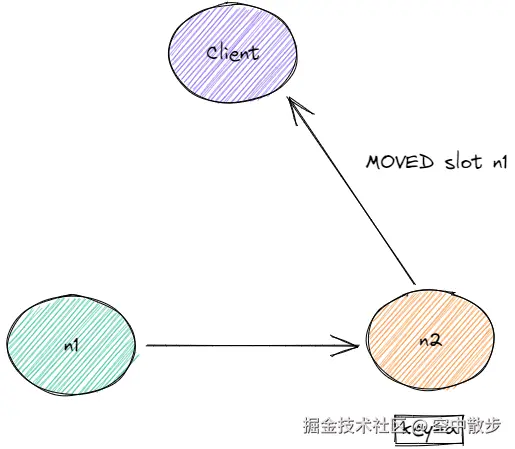
客户端收到MOVED响应, 再发送命令到n1: 如此往复, 直到重试次数达到maxRedirections=5.
解决方案
解决方法是显而易见的, 我们只需要保证asking命令和重定向的命令的发送保证是原子性的发送即可:

经过调研在Lettuce的6.0.0版本修复了, 之后我们升级了Lettuce版本, 最后解决了这个问题.
总结
好了问题排查完了, 现在总结一下本文的要点.
-
Slot迁移与ASK重定向
- 在Redis集群中,当slot从一个节点迁移到另一个节点时,原节点会返回ASK重定向指令,告知客户端目标slot现在位于哪个节点。
- 客户端在接收到ASK响应后,需要先向目标节点发送ASKING命令,再发送原始命令。
-
多线程共享连接的问题
- Lettuce框架允许多线程共享同一个Redis连接,这虽然提高了资源利用率,但在处理ASK重定向时可能引发问题。
- 如果在发送ASKING命令和原始命令之间,有其他线程通过共享连接发送了无关命令,就可能破坏ASKING命令和原始命令的原子性,导致目标节点返回MOVED响应,从而引发重试循环。
-
Lettuce的修复
- Lettuce在6.0.0版本中修复了这个问题,通过确保ASKING命令和后续命令的发送是原子性的,避免了因多线程共享连接导致的MOVED响应和不必要的重试。
发表回复