theme: cyanosis
📘 背景
这又是一个线上 Redis 大规模故障引发的案例,在上一次 Redis 缩容故障引发业务大面积不可用(见这篇文章:血的教训!Redis缩容导致线上大规模故障的惨痛经历 – 烈香的博客 (deadlock.cloud))之后,在我的操作之下居然又发生了一次故障,这次还是缩容引起的!\
哈哈😀缩容可能是我绕不过去的一个坎了,但再怎么说我也不会栽在同一个坑里两次,所以这次故障的原因和之前的不同,相信你一定猜不到🤭
🔥 故障现场
本次故障是进行 Redis 集群缩容过程中,迁移 slot 数据时,业务突然有大量 Redis 访问异常,报错信息如下,还是和上一次相似的 MOVED 异常:
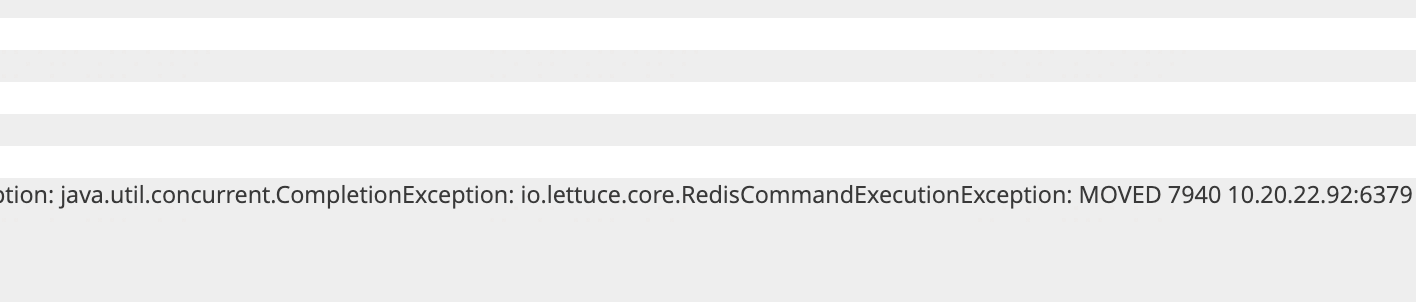
当我看到这个报错时,我并没有慌,因为我知道这是由于集群内部节点之间对于 slot 的归属不一致导致的。
小提示✔: redis 集群内部每个节点都维护了每个 slot 的 owner ,当客户端请求到任意一个 Redis 集群节点时,Redis 根据 key 算出 slot,再判断 slot 是否属于自己,如果不属于就会发送
MOVED slot ip异常返回给客户端,这样客户端就知道了 slot 的真正归属是谁,会再发送请求给正确的 Redis 节点。
当时报错信息具体是:MOVED 10.20.22.92 7940。我到 10.20.22.92 这台机器上使用 cluster nodes 命令查看集群信息,发现 slot 确实不在这台机器上:
root@sh2-arch-redis-product-prod-29 ~ $ redis-cli cluster nodes|grep self
7285477753679199e9238fbe94a00f1569661aea 10.20.22.92:6379@16379 myself,master - 0 1721140407000 35464 connected 7866-7929 ...可奇怪的是去其他 Redis 节点上执行使用 cluster nodes 命令查看发现 7940 这个 slot 确实在 10.20.22.92 上!
root@sh1-arch-redis-product-1 ~ $ redis-cli cluster nodes | grep 10.20.22.92
7285477753679199e9238fbe94a00f1569661aea 10.20.22 92:6379@16379 master - 0 1721140402000 35464 connected 7866-7942 ...为了确认 7940 这个 slot 到底发生了什么我专门查看了 Redis 日志,发现 7940 这个 slot 确实在 22:23 分已经迁移到了 10.20.22.92 上面,而业务异常大量报错的时间点在 22:24 分!
...
1803:M 16 Jul 2024 22:23:17.617 # configEpoch updated after importing slot 7940
1803:M 16 Jul 2024 22:23:21.088 # New configEpoch set to 35279
...小结
让我们梳理一下这次故障诡异的时间线:
22:23:17:根据日志发现 slot 7940 在 迁移到 10.20.22.92。\
22:24:03:客户端开始报错:MOVED 10.20.22.92 7940。\
22:29:12:开始排查,发现 10.20.22.92 不认为自己有 7940 这个 slot,反而是其他节点认为 7940 是 10.20.22.92 所有。
也就是说整个集群在 7940 这个 slot 的归属问题上脑裂了! 为什么已经迁移的 slot 在目标节点上会莫名消失?难道 Redis 有 bug ?(你别说还真是😅,往下看就知道)
🍳 深入了解 Redis 集群内部通信原理
要知道这个问题的原因,就不得不深入了解Redis集群内部到底是如何让slot分布达到一致的。下面就让我们一起深入Redis 内部探究吧。
Redis 集群如何传播 slot 分布?
Redis 集群内部每个节点通过 PING-PONG 的 Gossip 协议消息交互,消息内容主要包括两部分:
- 自己负责的 slot 和自己的
config epoch - 自己知道的一部分 Redis 节点的 ip,port 等
发送自己负责的 slot 就是为了保证 slot 分布信息在集群内部一致,另外还有一个 config epoch ,它可以理解为一个版本号,用于解决不同节点之间 slot 冲突,这里先简单介绍下,后面还有详细讲述。
具体是发送给谁怎么发送的呢? 答案是如下:
- 每秒选择1个最久没有 ping 过的节点发送
PING消息 - 同时也会确保在
cluster-node-timeout / 2 = 7500ms时间范围内,发送给还没有发送过 PING 消息的节点。
如果集群规模较大有上百个节点,第二步会完成大部分节点的发送,ping/pong 消息头中携带本节点负责的 slot 和 config epoch,因此可以用这个信息完成 slot 分布的传播。
💡 知识点1:集群规模比较大,slot变化的传播是需要时间的。
节点内部是如何处理 Gossip 协议消息的?
首先我们要知道 Redis 节点内部维护了几个重要的信息:
- 集群内其他节点的状态,包括节点的
configEpoch - 每个
slot的 owner ,是一个长度为16384的数组 currentEpoch和configEpoch:currentEpoch是这个集群所有节点中最大的configEpoch(当然这个值可能不是最新的),每个节点都有一个configEpoch(且大多数情况下每个节点的configEpoch是不同的,但也有出现相等的情况,具体冲突解决逻辑见下方)configEpoch代表slot分布的版本号,如果slot分布不一致,要靠configEpoch解决不一致。
dict *nodes;
/* Hash table of name -> clusterNode structures */
clusterNode *slots[CLUSTER_SLOTS];
uint64_t currentEpoch;
uint64_t configEpoch;那么回到主题:节点内部是如何处理gossip消息的呢?
假设有两个节点 A 和 B , A 发送给B一个 Gossip 消息,B 的处理逻辑为:
- 节点B 更新自己维护的 节点A 信息: 如果消息头里的
configEpoch更大的话,会更新自己维护的 节点A 的configEpoch。 - 如果节点A的
configEpoch和 节点B 的相等且自己的 NodeID 更小,节点B的 currentEpoch 增加一,并且作为自己的configEpoch,(意味着节点B使用了一个新的configEpoch,并且是集群中最大的——它自己认为的,因为currentEpoch有可能不是最新的) - 如果A节点声明的slot和自己维护的A拥有的slot有区别的话,根据ping消息声明的每个slot的config epoch的不同有如下操作:\
a. 如果消息头的config epoch比这个 slot 的 owner 的config epoch更大,那么更新这个 slot 的 owner。\
b. 如果消息头的config epoch比这个 slot 的 owner 的config epoch更小,说明发送方的 slot 分布是过时的,有些 slot 已经不属于发送方了,所以返回一个 UPDATE 消息,这个UPDATE消息里包含了这个slot owner 的 slot 分布和config epoch。 - 如果节点A 收到了
UPDATE包(注意这其实也是一个Gossip消息),节点A 会按照这个逻辑更新自己的 slot 分布。
让我来精简下这段逻辑:其实就是为了解决两个节点分别声明一个slot的归属权,而如何解决这种争议呢?看的是这两个节点config epoch的大小,谁比较大谁就“胜诉”。而且还要注意,如果一个节点“败诉”,它还会接收到一份“通知”,要求其更新slot的归属为胜诉方。
注意这里其实是一个覆盖操作,当我分析到这里的时候,我就知道离真相不远了。
💡 知识点二:当争夺归属权失败(由于自己的config epoch比较低),那么自己的slot会被覆盖
如果我们再靠近点分析,又可以发现一个盲点: 其实当一个节点的 slot 迁出去(减少)的时候,它发送的 Gossip 消息接收方是不会老实更新的,这其实和接收方的处理逻辑有关系:
举个栗子:\
节点B 上看 节点A 是如下 slot 的拥有者:slot:[1,2,3] \
之后 节点A 的 slot 迁出,变成了: [1,2]
再之后 节点A 发送 ping 到 节点B,节点B 不会更新 节点A 的 slot,节点B 上 节点A 的 slot 依然是:[1,2,3], 并不是 [1,2] , 只有等到 slot=3 的新 owner 发送 ping 消息且它的 epoch 更大,才会在节点B 更新 slot=3 的 owner。
💡 知识点三:一个节点slot迁出后,其他节点看这个节点的slot只有等到“正主”发送gossip协议消息才会更新。
那么在迁移 slot 的时候到底发生了什么?config epoch 是如何变化的?
迁移slot时到底发生了什么?
在迁移 slot 时,首先要从源节点上迁移数据,数据全部迁移好后,需要在对应节点上调用 cluster setslot slot nodeId 命令,彻底变更 slot 的归属,setslot 命令的具体逻辑如下:
- 设置自己维护的 slots 的 owner 为对应 nodeId 的节点
- 如果自己正在
imporing这个 slot,而且自己的configEpoch不是最大的,那么会增加currentEpoch,并且作为自己的configEpoch。
也会打印这样的日志:
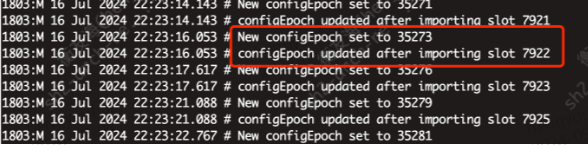
💡 知识点4:当一个节点slot迁入,其config epoch一般是全集群最高的
🎇 黑幕揭晓
综合以下条件,你会发现什么?
- slot 的变化传播需要时间。
- 当争夺归属权失败(由于自己的
config epoch比较低),那么自己的 slot 会被覆盖。- 一个节点 slot 迁出后,其他节点看这个节点的 slot 只有等到“正主”发送 gossip 协议消息才会更新。
- 当一个节点 slot 迁入,其
config epoch一般是全集群最高的。
让我来梳理下:
自己刚刚迁入的slot被覆盖,根据条件2可能是由于自己的config epoch不是最高的导致被覆盖了,那最高的是哪个节点?
很有可能是正在迁入的节点!
去查日志看看当时正在迁入的节点有哪些,也许能发现什么线索!
结果一看原来是这样\~,还记得 7940 这个 slot 和 10.20.22.92 这个目标节点吗,当时是 10.20.22.47 迁出7940 到 10.20.22.92 上,结果在 10.20.22.47 这个源节点上看到日志:

欸?10.20.22.47 居然在迁入 slot。。。
好了一切线索终于拼接起来,下面让我来还原案发现场…
还原那个现场…
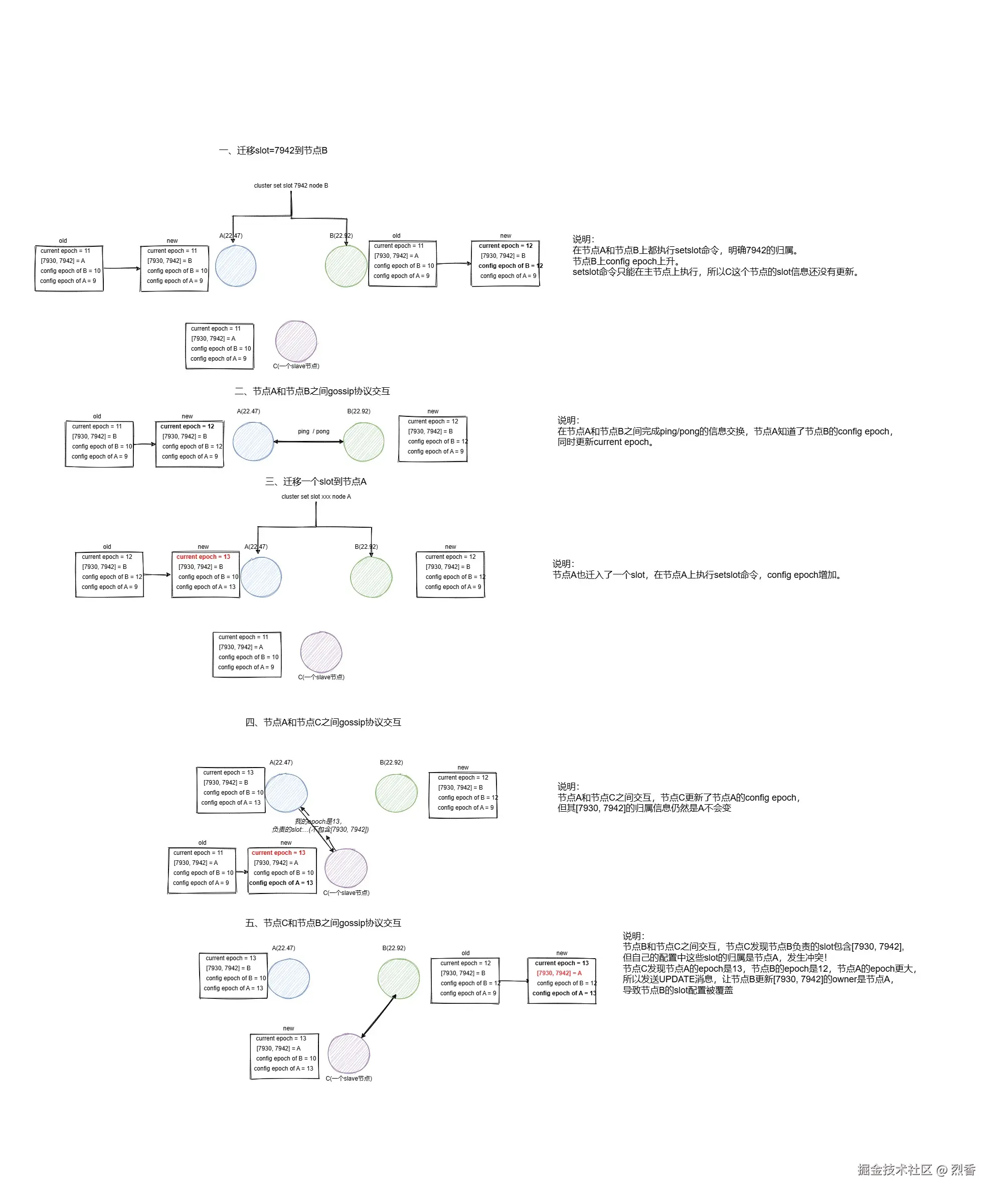
假设:(节点A = 10.20.22.47, 节点B = 10.20.22.92)\
场景:节点A原有slot=[1,2,3]epoch=2, 节点Bepoch=1,slot 从节点A 迁移 slot=3 到节点B
步骤:
- 在节点A 上执行
cluster setslot 3 node_B将 slot3 分配给节点B (也包括其他主节点)。 - 在节点B 上执行
cluster setslot 3 node_B,节点B epoch 增加为2 + 1 = 3。 - 节点A 接收到 B 的 ping 消息,
currentEpoch更新为3, 之后节点 A 由于同时发生迁入,epoch增加了(由于setslot命令),epoch= 3 + 1 = 4。 - 节点A 发送
ping传播自己的slot=[1,2]epoch=4给 节点C(任意一个从节点),节点C 上 节点A 的信息:slot[1,2,3],epoch=2更新为slot[1,2,3],epoch=4(节点C是从节点,因为主节点全部都执行了setslot,从节点是没办法执行setslot的)。 - 节点B 发送
ping到节点C,消息内容:slot=[3],epoch=3,由于epoch=3 < epoch=4, 因此 节点C 返回UPDATE包,返回 节点A 的 slot 分布,节点B 重置slot=[3]的 owner 为节点A。
我画了一张图,方便你理解
原因总结
一个节点在迁出 slot 的同时,又在迁入 slot,导致这个节点缩减的 slot 信息在传播到所有节点之前,其 epoch 由于迁入导致比目标节点还高,最终导致目标节点的 slot 分布被覆盖,进而引发惨案…
为什么一个节点在迁出 slot 的同时,又在迁入 slot 呢?
再次查看日志,原来是我在生成迁移计划的时候,误将这个节点同时作为源节点和目标节点,所以还是操作失误导致的😂
如何修复
- 社区中遇到类似问题的解决办法是在setslot执行后,等待拓扑传播完毕,再继续迁移其他节点
-
当源节点不再声明某些 slot 时,需要标记这些 slot 为不确定归属的 slot ,在目标节点发送 ping 并且声明这些 slot 时,应该能正常更新 slot 的归属,而不是由于
epoch较小被发送UPDATE消息。社区相关PR(已merge 到 Redis 社区主干,Redis7.0 版本后)https://github.com/redis/redis/pull/12344/files -
操作层面禁止一个节点同时迁入迁出slot
🧭 写在最后
这次故障分析过程还是比较酣畅淋漓的,大家看完一定有一些收获,代价只不过是我的绩效没了😅。
这次故障其实比较尴尬😅,因为其根本原因是由于 Redis 的 bug —— 同时迁入和迁出 slot 时会触发,但触发操作是我导致的,操作失误让一个节点同时迁入迁出 slot 了,所以大家还是注意线上操作要谨慎。
发表回复